Hi,
I’m doing some import tests to an Autonomous Database Serverless and I have a few things to share.
Usually, people use the dump files in an Object Storage, but you can also use it on an FSS.
The recommendation on the documentation is to use the Service High and .25 ECPU per parallel:

During my tests, I didn’t find a significant improvement using High.
Using the Service “Medium”:
19-FEB-24 18:52:21.314: Job “ADMIN”.”IMPFA16C001″ completed with 2062 error(s) at Mon Feb 19 18:52:21 2024 elapsed 0 03:20:37
Using the Service “High”:
19-FEB-24 18:44:23.714: Job “ADMIN”.”IMPFA16D001″ completed with 2062 error(s) at Mon Feb 19 18:44:23 2024 elapsed 0 03:12:06
Using the Service “TPUrgent”:
19-FEB-24 18:49:17.714: Job “ADMIN”.”IMPFA16E001″ completed with 2062 error(s) at Mon Feb 19 18:49:17 2024 elapsed 0 03:16:46
Some tips:
1 – How do you get the import log file?
SELECT * FROM DBMS_CLOUD.LIST_FILES(‘DATA_PUMP_DIR’);
BEGIN
DBMS_CLOUD.PUT_OBJECT(
credential_name => ‘obj_store_cred’,
object_uri => ‘https://swiftobjectstorage.us-sanjose-1.oraclecloud.com/v1/awesdasdq/bucket_az/importb9.log’,
directory_name => ‘DATA_PUMP_DIR’,
file_name => ‘import.log’);
END;
/
2 – How to monitor the alert.log?
select * from V$DIAG_ALERT_EXT;
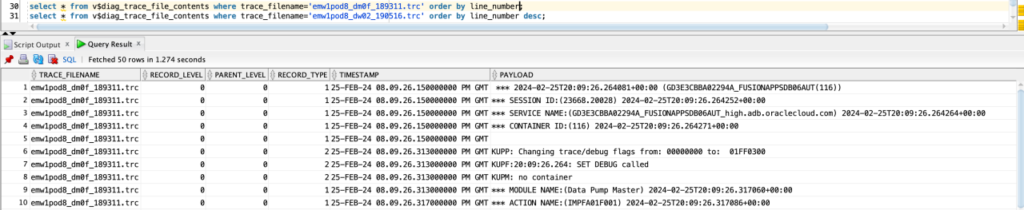
3 – How to see the content of the Data Pump trace files in the Autonomous Database?
v$diag_trace_file

v$diag_trace_file_contents
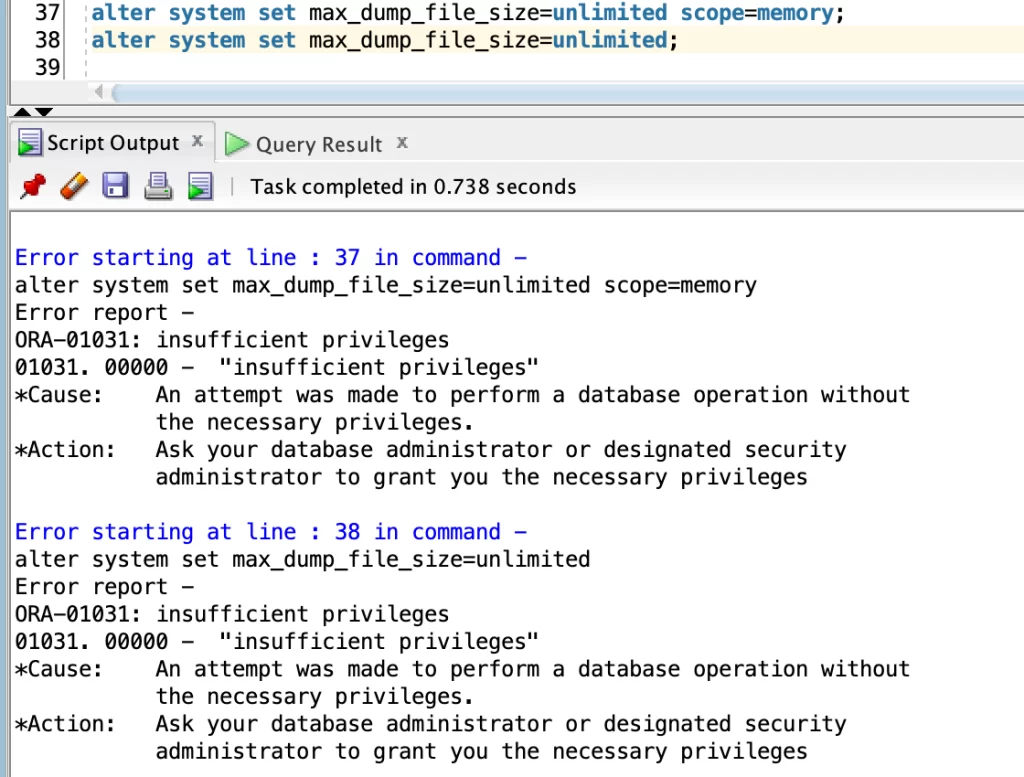
Unfortunately, we still have one limitation related to the size of the trace file:


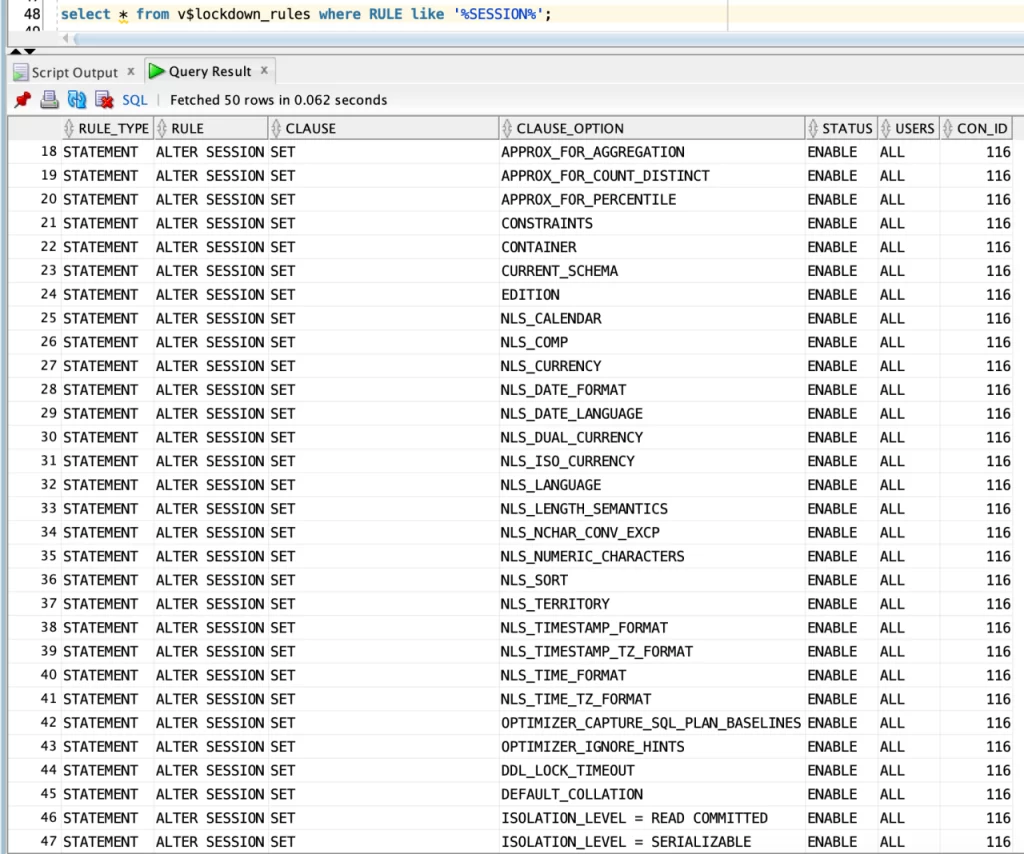
You can use the v$lockdown_rules to check for the lockdown profile limitations: